.
5
assets/css/all.min.css
vendored
Normal file
BIN
assets/img/cursed_udm_fetch.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 136 KiB |
BIN
assets/img/eyecrop.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 193 KiB |
BIN
assets/img/large.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.2 MiB |
BIN
assets/img/medium.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.1 MiB |
BIN
assets/img/she_doesnt_exist.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2 MiB |
BIN
assets/img/small.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 317 KiB |
BIN
assets/img/trashcan.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 144 KiB |
BIN
assets/mov/darkest_corners_of_the_internet.mp4
Normal file
46
index.html
Normal file
|
|
@ -0,0 +1,46 @@
|
|||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>despera.space</title>
|
||||
<style>
|
||||
body {
|
||||
background-color: #002b36; /* Base03 - Background */
|
||||
color: #839496; /* Base0 - Foreground */
|
||||
}
|
||||
|
||||
a {
|
||||
color: #268bd2; /* Blue - Link */
|
||||
}
|
||||
|
||||
a:hover {
|
||||
color: #2aa198; /* Cyan - Link Hover */
|
||||
}
|
||||
|
||||
h1 {
|
||||
color: #b58900; /* Yellow - Header */
|
||||
}
|
||||
|
||||
ul {
|
||||
list-style-type: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
li {
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<h1>IDs</h1>
|
||||
<li>NPUB: npub1nmk2399jazpsup0vsm6dzxw7gydzm5atedj4yhdkn3yx7jh7tzpq842975</li>
|
||||
<li>NIP06: iru@ this domain</li>
|
||||
<li>LNURL: iru@ this domain</li>
|
||||
<li>GPG: 0DE8AAA9F5DA9CCB3F3F3B8E14566DCEC81EF576</li>
|
||||
<li>Github: irusensei</li>
|
||||
<h1>Long form notes</h1>
|
||||
<li>Running popular AI software on Linux and AMD GPUs: <a href="https://habla.news/a/naddr1qqxnzd3ex56rwvfexvurxwfjqgsfam9gjjew3qcwqhkgdax3r80yzx3d6w4uke2jtkmfcjr0ftl93qsrqsqqqa28vfwv5f">note</a>, <a href="https://code.despera.space/iru/htdocs/src/branch/main/notes/AMD-AGI.md">local</a></li>
|
||||
<li>How I put NixOS on my UDM (trashcan model) router: <a href="https://habla.news/a/naddr1qvzqqqr4gupzp8hv4z2t96yrpcz7eph56yvausg69hf6hjm92fwmd8zgda90ukyzqqxnzde3xccnyd3sxver2dfk5j9lzf">note</a>, <a href="https://code.despera.space/iru/htdocs/src/branch/main/notes/UDM-NIXOS.md">local</a>
|
||||
<h1>Other stuff</h1>
|
||||
<li><a href="https://code.ide-roach.ts.net/mirrors">I keep mirrors of repos I use or feel like having preserved</a>.</li>
|
||||
</body>
|
||||
</html>
|
||||
59
index.md
Normal file
|
|
@ -0,0 +1,59 @@
|
|||
# Iru Sensei
|
||||
*Location: Krakow, Poland - as a temporary resident*
|
||||
*Email: shires-supply-0n@icloud.com*
|
||||
*LinkedIn: Upon Request*
|
||||
*GitHub: [irusensei](https://github.com/irusensei)*
|
||||
*npub: npub1nmk2399jazpsup0vsm6dzxw7gydzm5atedj4yhdkn3yx7jh7tzpq842975*
|
||||
|
||||
## Summary
|
||||
I'd describe myself as a Linux system administrator, and on top of that, I layer some marketable skills like devops with a dash of development. Throughout my career, I've found this combination to be quite handy, whether I'm working with legacy heavyweight infrastructure running commercial Unix flavors or writing deployment pipelines and container manifestos.
|
||||
|
||||
I've got a solid understanding of Kubernetes and manifesto writing, though I haven't pigeonholed myself into specific plugins or controllers – I like to keep things flexible.
|
||||
|
||||
I'm familiar with cloud providers, especially with Azure, thanks to my current job. I lean towards agnostic technologies, favoring tools like Terraform for my cloud API interactions.
|
||||
|
||||
I can code, although I wouldn't label myself a full-fledged developer. I'm proficient at automation and handling non-business logic, like creating helper modules and keeping things in good shape.
|
||||
|
||||
I run bitcoin software at home. Normally core, fulcrum and LND plus LNBits to interface with the Lightning network. Having tried many alternatives (including an ill fated k3s instance, running and compiling my own containers etc) I've setled with Nix-Bitcoin.
|
||||
|
||||
Lastly, I'm well-versed in the responsibilities that come with financial IT, which includes a healthy awareness of client data confidentiality and "must-knows" that come with the territory of working with an European bank.
|
||||
|
||||
## Work Experience
|
||||
### Job Title - Company Name (City, State) | Date - Present
|
||||
* Can provide details upon request. Here is a list of past jobs without mentioning company names:
|
||||
- Consultant for SuSE Linux Enterprise partner. Key products included virtualization (Xen), LDAP, mail and web servers.
|
||||
- System administration for an online gaming company. Key products included maintaining Linux and FreeBSD application and web servers.
|
||||
- System administration for logistics tracking company. Mainly virtualization (Xen) Linux system administration.
|
||||
- System Engineer on SuSE Linux Enterprise partner (same company). This time with heavy focus on monitoring projects (Nagios, Centreon, writing custom monitoring program).
|
||||
- System Engineer on retail store chain. Besides Linux system administration (mostly SAP on Linux) I wrote the deployment scripts for every in store server and PoS and monitoring.
|
||||
- Senior configuration engineer on current job. On site on a too-big-to-fail european bank. Working on a team whose focus is to maintain Azure monitoring and automation platforms and integration between cloud and on-prem systems. I handle infrastructure and CI/CD.
|
||||
|
||||
|
||||
## Education
|
||||
### Degree Name - University Name (City, State) | Date
|
||||
- I only finished high school and scored a minor IT job after finishing.
|
||||
|
||||
## Skills
|
||||
* General keywords:
|
||||
- Linux, Unix, Windows, Docker, Containers, Kubernetes, Gitlab, Terraform, Cloud.
|
||||
* Languages:
|
||||
- Bash, Python, Powershell, Golang.
|
||||
|
||||
## Certifications
|
||||
- I have LPI and SuSE Enterprise Engineer certifications but most of these are probably expired.
|
||||
|
||||
## Languages
|
||||
- English, portuguese.
|
||||
|
||||
## Interests
|
||||
- Operating systems from a system administrator perspective.
|
||||
- Open source.
|
||||
- Self hosting.
|
||||
- Bitcoin and sovereign financial technology.
|
||||
- Internet freedom.
|
||||
- Lately been interested in Nostr.
|
||||
|
||||
## References
|
||||
|
||||
Personal details like personal info and Linkedin profile pages can be granted upon request.
|
||||
|
||||
514
notes/AMD-AGI.md
Normal file
|
|
@ -0,0 +1,514 @@
|
|||
Here is how to get popular AI software running on a recent RDNA or RDNA2 AMD card. This method uses distrobox so it should be the same for every Linux distribution.
|
||||
|
||||
There is always a chance these instructions would be deprecated in a few months.
|
||||
|
||||
## Requirements
|
||||
|
||||
### Hardware
|
||||
|
||||
All RDNA iterations should work possibly with slightly different steps and versions. Polaris and Vega are also known to work but some parameters might be different. I can only test these results on my RX 6800m.
|
||||
|
||||
### Software
|
||||
|
||||
The main advantage AMD has over Nvidia on Linux is the mainline open source driver working out of the box. Installing amdgpu-pro defats the purpose so you might as well buy Nvidia if you are to use binary blobs.
|
||||
|
||||
I recommend a recent kernel in order to make use of the drivers available on mainline kernel and avoid using the proprietary amdgpu-pro driver. The one included on Ubuntu 22.04 LTS should suffice which is around 5.4.14 but chances are you are on 6.x.
|
||||
|
||||
The first step is to install [distrobox](https://github.com/89luca89/distrobox). On Nixos I've achieved that by adding the distrobox package to my user list of packages. If distrobox is not available on your package manager follow the instructions on the project page to get it installed.
|
||||
|
||||
On Fedora the package [toolbox](https://docs.fedoraproject.org/en-US/fedora-silverblue/toolbox/) works in a similar fashion. In fact both programs run on top of Podman rootless containers.
|
||||
|
||||
This article has been created on a system running the current version of Nixos (23.11). It shouldn't matter what you are running as long as you have a proper kernel and can run Podman rootless containers.
|
||||
|
||||
### Access rights
|
||||
|
||||
Your user must have access to /dev/kfd and /dev/dri/* devices. Normally these belong to root user and render group. This is done by default on most desktop distributions but if you are not on the render group add yourself to it and restart your session.
|
||||
|
||||
Find out which group owns /dev/kfd:
|
||||
```
|
||||
$ ls -l /dev/kfd
|
||||
crw-rw-rw- 1 root render 242, 0 Sep 13 15:35 /dev/kfd
|
||||
```
|
||||
|
||||
Find out if I belong to group render.
|
||||
|
||||
```
|
||||
$ groups
|
||||
users wheel video render
|
||||
```
|
||||
|
||||
I'm case I'm not, assuming my username is iru I can do this by:
|
||||
|
||||
```
|
||||
$ gpasswd -a iru render
|
||||
```
|
||||
|
||||
Then just exit desktop or ssh session and log in again. A reboot is not needed.
|
||||
|
||||
## Preparing environment and installing libraries
|
||||
|
||||
### Initializing distrobox
|
||||
|
||||
First I recommend creating a separate home for your distroboxes. The reason behind it being some compiler environment variables you might not want to mix with your main system. Here I'm going to use ~/Applications/rocm6.
|
||||
|
||||
|
||||
```bash
|
||||
mkdir -p ~/Applications/rocm6
|
||||
```
|
||||
|
||||
|
||||
|
||||
You will be asked confirmation for the commands bellow.
|
||||
|
||||
```
|
||||
distrobox create -n rocm6 --home /home/iru/Applications/rocm6 --image docker.io/library/ubuntu:22.04
|
||||
```
|
||||
|
||||
Now we can enter the distrobox container:
|
||||
|
||||
```
|
||||
$ distrobox enter rocm6
|
||||
Starting container rocm
|
||||
|
||||
...
|
||||
|
||||
Container Setup Complete!
|
||||
```
|
||||
|
||||
You are now inside a rootless (user level, non administrative) container integrated with your home folder and system devices. You can access your files and folders but with no visibility to the world outside your home folder. The operating system is now Ubuntu 22.04 regardless of the underlying distribution.
|
||||
|
||||
* You can sudo and install programs into this toolbox using apt.
|
||||
* The root superuser inside this environment is not the same as your system root user.
|
||||
* Programs installed through the system do not affect your underlying system.
|
||||
* Deleting the distrobox will have no affect on your system.
|
||||
* Your home is still mapped therefore if you delete your personal files those will be gone for good.
|
||||
* Programs installed locally through your user folder (i.e. Go, Rust stuff) might work as normal.
|
||||
* Since we opted to set ~/Applications/rocm6 as the home folder the dot files will be separate from your main system.
|
||||
|
||||
Regardless of how you've arrived here, you should have an Ubuntu 22.04 environment with access to /dev/kfd and /dev/dri/* on your system.
|
||||
|
||||
It is a good idea to update the system before we begin installing dependencies.
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt upgrade -y
|
||||
```
|
||||
|
||||
### Installing ROCm
|
||||
|
||||
Now lets install ROCm and other packages by following the instructions on the [AMD documentation site for ROCM](https://rocm.docs.amd.com/projects/install-on-linux/en/latest/how-to/native-install/ubuntu.html).
|
||||
|
||||
|
||||
Import the signing keys into the distrobox container.
|
||||
```
|
||||
$ sudo mkdir --parents --mode=0755 /etc/apt/keyrings
|
||||
$ wget https://repo.radeon.com/rocm/rocm.gpg.key -O - | gpg --dearmor | sudo tee /etc/apt/keyrings/rocm.gpg > /dev/null
|
||||
...
|
||||
2024-05-07 14:03:18 (2.61 GB/s) - written to stdout [3116/3116]
|
||||
|
||||
```
|
||||
|
||||
Now we register the runtime repos.
|
||||
```
|
||||
$ echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/amdgpu/6.1/ubuntu jammy main" | sudo tee /etc/apt/sources.list.d/amdgpu.list
|
||||
$ echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/rocm/apt/6.1 jammy main" | sudo tee --append /etc/apt/sources.list.d/rocm.list
|
||||
$ echo -e 'Package: *\nPin: release o=repo.radeon.com\nPin-Priority: 600'| sudo tee /etc/apt/preferences.d/rocm-pin-600
|
||||
$ sudo apt update
|
||||
```
|
||||
|
||||
Install ROCm. No need to install the proprietary drivers.
|
||||
```
|
||||
$ apt install rocm
|
||||
```
|
||||
|
||||
Optionally you might also want to install radeontop a useful TUI resource monitor.
|
||||
|
||||
```
|
||||
$ sudo apt install radeontop
|
||||
```
|
||||
|
||||
The rocm-smi monitor:
|
||||
|
||||
```
|
||||
$ rocm-smi
|
||||
========================= ROCm System Management Interface =========================
|
||||
=================================== Concise Info ===================================
|
||||
ERROR: GPU[1] : sclk clock is unsupported
|
||||
====================================================================================
|
||||
GPU[1] : get_power_cap, Not supported on the given system
|
||||
GPU Temp (DieEdge) AvgPwr SCLK MCLK Fan Perf PwrCap VRAM% GPU%
|
||||
0 50.0c 22.0W 500Mhz 96Mhz 40.78% auto 130.0W 0% 3%
|
||||
1 57.0c 31.0W None 1600Mhz 0% auto Unsupported 77% 0%
|
||||
====================================================================================
|
||||
=============================== End of ROCm SMI Log ================================
|
||||
```
|
||||
|
||||
The rocminfo command:
|
||||
|
||||
```
|
||||
$ rocminfo
|
||||
```
|
||||
|
||||
Lots of devices here. I'm running one of those laptops with hybrid GPUs so it prints details about the integrated graphics unit on the Ryzen processor plus the discrete 6800m GPU. There is also a third virtual device that acts as a mux between discrete and integrated GPUs.
|
||||
|
||||
In my case this is the relevant part:
|
||||
|
||||
```
|
||||
*******
|
||||
Agent 2
|
||||
*******
|
||||
Name: gfx1031
|
||||
Uuid: GPU-XX
|
||||
Marketing Name: AMD Radeon RX 6800M
|
||||
```
|
||||
|
||||
From my personal experience APUs don't work.
|
||||
|
||||
Next we need to add some environment variables.
|
||||
|
||||
```
|
||||
export CC=/opt/rocm/llvm/bin/clang
|
||||
export CXX=/opt/rocm/llvm/bin/clang++
|
||||
export PATH=/opt/rocm/bin:/opt/rocm/opencl/bin:$PATH
|
||||
```
|
||||
|
||||
Another variable that needs to be set is `HSA_OVERRIDE_GFX_VERSION`. AMD doesn't actually support ROCm on consumer grade hardware so you need this variable to force it use a certain target. Remember rocminfo? It gave me a "gfx1031" for my 6800m so going to set this variable as "10.3.0" which would apply to 1030, 1031, 1032 and so on. For non RDNA cards we need to setup values for Vega (GCN5) which would be 9.0.0. RDNA3 uses "11.0.0".
|
||||
|
||||
```bash
|
||||
export CC=/opt/rocm/llvm/bin/clang
|
||||
export CXX=/opt/rocm/llvm/bin/clang++
|
||||
export PATH=/opt/rocm/bin:/opt/rocm/opencl/bin:$PATH
|
||||
export HSA_OVERRIDE_GFX_VERSION="10.3.0"
|
||||
```
|
||||
|
||||
Finally source the shell configuration file or exit the session and log in again and verify the environment variables are properly set.
|
||||
|
||||
```
|
||||
$ source ~/.profile
|
||||
$ echo $CC
|
||||
/opt/rocm/llvm/bin/clang
|
||||
$ echo $CXX
|
||||
/opt/rocm/llvm/bin/clang++
|
||||
```
|
||||
|
||||
## Installing software
|
||||
|
||||
Following are instructions to install Stable Diffusion webui, ooba's text generation ui and Langchain.
|
||||
|
||||
|
||||
### Git
|
||||
```
|
||||
apt install git python3.10 python3.10-venv
|
||||
```
|
||||
|
||||
### Voice Changer
|
||||
|
||||
```
|
||||
$ sudo apt install libportaudio2
|
||||
$ cd
|
||||
$ git clone https://github.com/w-okada/voice-changer.git
|
||||
$ cd voice-changer
|
||||
$ python3 -m venv venv
|
||||
$ source venv/bin/activate
|
||||
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.0
|
||||
$ cd server
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
### Stable Diffusion WebUI
|
||||
|
||||
The most popular way to interact with Stable Diffusion is through AUTOMATIC1111's Gradio webui. Stable diffusion depends on Torch.
|
||||
|
||||
We start by cloning the Automatic1111 project into our home folder.
|
||||
|
||||
```
|
||||
$ cd
|
||||
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
|
||||
$ cd stable-diffusion-webui
|
||||
```
|
||||
|
||||
This project changes a lot so for your sanity I recommend switching to the last release (1.6.0 at the time of this writing).
|
||||
|
||||
```
|
||||
$ git checkout v1.6.0
|
||||
```
|
||||
|
||||
On Nvidia or pure CPU you just need to run webui.sh and have all the software and dependencies installed AMD requires that you define an alternative source for the libraries besides setting certain environment variables.
|
||||
|
||||
The file we are looking for is webui-user.sh where custom configuration can be added.
|
||||
|
||||
The first one is `TORCH_COMMAND` which defines how Torch should be installed. By going to [https://pytorch.org](https://pytorch.org) and scrolling down til you see an "INSTALL PYTORCH" with a selection box.
|
||||
|
||||
* Choose Stable (at the time of this article is 2.0.1)
|
||||
* Choose Linux
|
||||
* Choose Pip
|
||||
* Choose ROCm (at the time of this article is 5.4.2)
|
||||
|
||||
You will get something like this:
|
||||
|
||||
```
|
||||
Run this Command: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
||||
```
|
||||
|
||||
The above command should also be enough if you just want to play with PyTorch.
|
||||
|
||||
Torch+ROCm doesn't necessarily needs to match the ROCm version you have installed. Of course matching versions would ensure best compatibility but it seems to not always be the case. I've tried the nightly Torch+ROCm 5.6 together with matching ROCm runtime version and it couldn't detect CUDA support.
|
||||
|
||||
So add this to webui-user.sh and make sure it's the only occurrence of `TORCH_COMMAND`. You probably don't need torchaudio.
|
||||
|
||||
```
|
||||
export TORCH_COMMAND="pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/rocm5.4.2"
|
||||
```
|
||||
|
||||
An optional setting is telling Torch how to manage memory. Aparently using the CUDA runtime (in our case ROCm passing as CUDA) native memory management is more efficient.
|
||||
|
||||
```
|
||||
export PYTORCH_CUDA_ALLOC_CONF="backend:cudaMallocAsync"
|
||||
```
|
||||
|
||||
Now the Command-line args to the program. In my experience the `--precision full --no-half --opt-sub-quad-attention` arguments will offer the best compatibility for AMD cards.
|
||||
|
||||
```
|
||||
export COMMANDLINE_ARGS="--precision full --no-half --opt-sub-quad-attention --deepdanbooru"
|
||||
```
|
||||
|
||||
If your card supports fp16 you can replace `--precision full --no-half` with `--upcast-sampling` for better performance and more efficient memory management. This is the case for at least RDNA2.
|
||||
|
||||
Here is the list of possible arguments: [https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings). A dedicated AMD session exists in [https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs) and might have up to date instructions.
|
||||
|
||||
So my webui-user.sh would look like this:
|
||||
|
||||
```
|
||||
export HSA_OVERRIDE_GFX_VERSION="10.3.0"
|
||||
export PYTORCH_CUDA_ALLOC_CONF="backend:cudaMallocAsync"
|
||||
export COMMANDLINE_ARGS="--precision full --no-half --opt-sub-quad-attention --deepdanbooru"
|
||||
export TORCH_COMMAND="pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/rocm5.4.2"
|
||||
```
|
||||
|
||||
A general tip is to copy that file somewhere else or add it to .gitignore. This file is tracked so if you run something like git reset --hard you might lose it.
|
||||
|
||||
Now run ./webui.sh.
|
||||
|
||||
```
|
||||
$ ./webui.sh
|
||||
################################################################
|
||||
Install script for stable-diffusion + Web UI
|
||||
Tested on Debian 11 (Bullseye)
|
||||
################################################################
|
||||
|
||||
################################################################
|
||||
Running on iru user
|
||||
################################################################
|
||||
|
||||
################################################################
|
||||
Repo already cloned, using it as install directory
|
||||
################################################################
|
||||
|
||||
################################################################
|
||||
Create and activate python venv
|
||||
################################################################
|
||||
|
||||
################################################################
|
||||
Launching launch.py...
|
||||
################################################################
|
||||
Cannot locate TCMalloc (improves CPU memory usage)
|
||||
Python 3.10.11 (main, Apr 5 2023, 00:00:00) [GCC 12.2.1 20221121 (Red Hat 12.2.1-4)]
|
||||
Version: v1.6.0
|
||||
Commit hash: 5ef669de080814067961f28357256e8fe27544f4
|
||||
Installing torch and torchvision
|
||||
Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/rocm5.4.2
|
||||
Collecting torch
|
||||
Downloading https://download.pytorch.org/whl/rocm5.4.2/torch-2.0.1%2Brocm5.4.2-cp310-cp310-linux_x86_64.whl (1536.4 MB)
|
||||
```
|
||||
|
||||
Some installation mumbo jumbo, yellow font pip warnings and a bunch of large files downloaded later you'll see something like this:
|
||||
|
||||
```
|
||||
Applying attention optimization: sub-quadratic... done.
|
||||
Model loaded in 8.2s (calculate hash: 2.6s, load weights from disk: 0.1s, create model: 2.9s, apply weights to model: 2.1s, calculate empty prompt: 0.4s).
|
||||
```
|
||||
|
||||
If you see some message recommending you to skip CUDA then something wrong happened, you are missing some library or don't have access to the /dev/kfd and /dev/dri/* devices.
|
||||
|
||||
If everything is correct you should open your browser pointing it to http://localhost:7860 and start generating images. It needs to compile some stuff so the first image you try to generate might take a while to start. Subsequent gens will be faster.
|
||||
|
||||
If you encounter errors while starting or generating images related to image either adjust your parameters or set `--medvram` or `--lowvram` to `COMMANDLINE_ARGS` on webui-user.sh, at the cost of performance of course.
|
||||
|
||||
OOM errors typically look like this:
|
||||
|
||||
|
||||
```
|
||||
torch.cuda.OutOfMemoryError: HIP out of memory. Tried to allocate 5.06 GiB (GPU 0; 11.98 GiB total capacity; 7.99 GiB already allocated; 3.39 GiB free; 8.50 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF
|
||||
```
|
||||
|
||||
It must be said that not even Nvidia users can generate high res images out of the box. The general strategy is to generate small images (like 512x512 or 768x768) and then use Hires Fix to upscale it.
|
||||
|
||||
#### SDXL
|
||||
|
||||
SDXL works like any model but bigger. If you get OOM errors while trying to generate images with SDXL add `--medvram-sdxl` to `COMMANDLINE_ARGS`. Again at a performance cost.
|
||||
|
||||
### Llama.cpp
|
||||
|
||||
Starting from commit 6bbc598 llama.cpp supports ROCm. Previous versions supported AMD through OpenCL. This project also changes and breaks very fast so stick to releases.
|
||||
|
||||
Make sure you've followed the step where we set the environment variables specially for the compilers.
|
||||
|
||||
```
|
||||
$ cd
|
||||
$ git clone https://github.com/ggerganov/llama.cpp.git
|
||||
$ cd llama.cpp
|
||||
$ git checkout b1266
|
||||
```
|
||||
|
||||
Use cmake. GNU Make compiles a binary that segfaults while loading the models.
|
||||
|
||||
```
|
||||
$ mkdir build
|
||||
$ cd build
|
||||
$ CC=/opt/rocm/llvm/bin/clang CXX=/opt/rocm/llvm/bin/clang++ cmake .. -DLLAMA_HIPBLAS=ON
|
||||
$ cmake --build .
|
||||
$ cp main ..
|
||||
```
|
||||
|
||||
The variables are not really needed since we already defined in the profile but I'm writing it anyway just to stress how they are needed.
|
||||
|
||||
If everything went alright you should see this message at the end.
|
||||
|
||||
```
|
||||
==== Run ./main -h for help. ====
|
||||
```
|
||||
|
||||
That's it. Look for scripts under examples to find out how to use the program. You need to pass the `-ngl N` argument to load a number of layers into the video RAM. A convenient feature of llama.cpp is that you can offload some of the model data into your normal generic RAM, again at the cost of speed. So if you have plenty of vram+ram and are not in a hurry you can run a 70b model.
|
||||
|
||||
Current llama.cpp uses a format named GGUF. You can download open source models from hugging face.
|
||||
I'm going to use [CodeLlama-13B-Instruct-GGUF](https://huggingface.co/TheBloke/CodeLlama-13B-Instruct-GGUF).
|
||||
|
||||
Check the quant method table under the model card. It tells how much memory that quantization uses. As a general rule I use Q4_K_M or Q5_K_M. Anything bellow Q4_K_M is often weird.
|
||||
|
||||
If you are sure the whole model fits in your VRAM (check the quant method table) just give some ridiculous value to -ngl like 1000. If that's not the case you need to make sure you pass enough layers to not OOM. I recommend to leave a bit of space on your VRAM for some swapping otherwise it will be painfully slow. So if you have 12GB VRAM make sure to pass enough layers to stay around 10GB and offload the rest to RAM.
|
||||
|
||||
```
|
||||
$ curl -L -o ./models/codellama-13b-instruct.Q4_K_M.gguf https://huggingface.co/TheBloke/CodeLlama-13B-Instruct-GGUF/resolve/main/codellama-13b-instruct.Q4_K_M.gguf
|
||||
$ ./examples/chat-13B.sh -ngl 1000 -m ./models/codellama-13b-instruct.Q4_K_M.gguf
|
||||
```
|
||||
|
||||
|
||||
A possible hiccup if you have more than one AMD GPU device (including the APU) you might get stuck in this:
|
||||
|
||||
```
|
||||
Log start
|
||||
main: warning: changing RoPE frequency base to 0 (default 10000.0)
|
||||
main: warning: scaling RoPE frequency by 0 (default 1.0)
|
||||
main: build = 1269 (51a7cf5)
|
||||
main: built with cc (GCC) 12.2.1 20221121 (Red Hat 12.2.1-4) for x86_64-redhat-linux
|
||||
main: seed = 1695477515
|
||||
ggml_init_cublas: found 2 ROCm devices:
|
||||
Device 0: AMD Radeon RX 6800M, compute capability 10.3
|
||||
Device 1: AMD Radeon Graphics, compute capability 10.3
|
||||
```
|
||||
|
||||
So we need to force it to use the proper device by passing `HIP_VISIBLE_DEVICES=N` to the script:
|
||||
|
||||
```
|
||||
$ export HIP_VISIBLE_DEVICES=0
|
||||
$ ./examples/chat-13B.sh -ngl 1000 -m ./models/codellama-13b-instruct.Q4_K_M.gguf
|
||||
```
|
||||
|
||||
If that's the case then add `HIP_VISIBLE_DEVICES=0` to your shell profile.
|
||||
|
||||
If everything went fine you'll be presented with an interactive chat with a bot on your terminal. Pay attention to the messages before the prompt and look for this:
|
||||
|
||||
```
|
||||
llm_load_tensors: VRAM used: 9014 MB
|
||||
....................................................................................................
|
||||
llama_new_context_with_model: kv self size = 1600.00 MB
|
||||
llama_new_context_with_model: compute buffer total size = 381.47 MB
|
||||
llama_new_context_with_model: VRAM scratch buffer: 380.00 MB
|
||||
|
||||
system_info: n_threads = 8 / 16 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
|
||||
```
|
||||
|
||||
Important here is how much VRAM is used and if BLAS = 1. If BLAS =0 you might be running on slower CPU AVX. If you are offloading layers (as in offloading part of a model larger than your vram to your ram) adjust the number of layers to fit in your vram, again with some slack for swapping.
|
||||
|
||||
If everything is correct you'll be able to make it output bullshit really fast.
|
||||
|
||||
```
|
||||
Text transcript of a never ending dialog, where USER interacts with an AI assistant named ChatLLaMa.
|
||||
ChatLLaMa is helpful, kind, honest, friendly, good at writing and never fails to answer USER's requests immediately and with details and precision.
|
||||
There are no annotations like (30 seconds passed...) or (to himself), just what USER and ChatLLaMa say aloud to each other.
|
||||
The dialog lasts for years, the entirety of it is shared below. It's 10000 pages long.
|
||||
The transcript only includes text, it does not include markup like HTML and Markdown.
|
||||
|
||||
USER: Hello, ChatLLaMa!
|
||||
ChatLLaMa: Hello USER! How may I help you today?
|
||||
USER: What year is it?
|
||||
ChatLLaMa: We are in 2023.
|
||||
USER: Please tell me the largest city in Europe.
|
||||
ChatLLaMa: The largest city in Europe is Moscow, the capital of Russia.
|
||||
USER: What can you tell me about Moscow?
|
||||
ChatLLaMa: Moscow, on the Moskva River in western Russia, is the nation's cosmopolitan capital. In its historic core is the Kremlin, a complex that's home to the president and tsarist treasures in the Armoury. Outside its walls is Red Square, Russia’s symbolic center.
|
||||
USER: What is a cat?
|
||||
ChatLLaMa: A cat is a domestic species of small carnivorous mammal. It is the only domesticated species in the family Felidae.
|
||||
USER: How do I pass command line arguments to a Node.js program?
|
||||
ChatLLaMa: The arguments are stored in process.argv.
|
||||
|
||||
argv[0] is the path to the Node. js executable.
|
||||
argv[1] is the path to the script file.
|
||||
argv[2] is the first argument passed to the script.
|
||||
argv[3] is the second argument passed to the script and so on.
|
||||
USER: Name a color.
|
||||
ChatLLaMa: Blue.
|
||||
USER: What time is it?
|
||||
ChatLLaMa: It is 17:46.
|
||||
USER: How to write hello world in ADA.
|
||||
ChatLLaMa: To write "Hello World" in Ada, you need to create an empty project called "hello_world", then open your text editor (like Visual Studio Code or Sublime Text) and add the following code to it:
|
||||
with Ada.Text_IO; use Ada.Text_IO; with Ada.Integer_Text_IO; use Ada.Integer_Text_IO; procedure HelloWorld is begin Put("Hello World"); NewLine; end HelloWorld; begin HelloWorld; end;
|
||||
|
||||
Then save the file as "hello_world.adb". Finally run the program by opening the terminal window and typing the command "gnatmake -P hello_world.gpr" and press enter key. Then wait for few seconds until the program finishes running and shows the output result on the screen.
|
||||
```
|
||||
|
||||
### Oobabooga's text-generation-webui and llama-cpp-python
|
||||
|
||||
This is a Gradio UI for LLMs. It listens on the same port as stable diffusion webui.
|
||||
|
||||
```
|
||||
$ cd
|
||||
$ git clone https://github.com/oobabooga/text-generation-webui.git
|
||||
$ cd text-generation-webui
|
||||
$ python3 -m venv ooba
|
||||
$ source ooba/bin/activate
|
||||
# for fish run "source ooba/bin/activate.fish" instead
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
We need to replace the llama-cpp-python lib with one that has ROCm support.
|
||||
|
||||
```
|
||||
$ pip uninstall llama-cpp-python
|
||||
$ CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install --no-cache llama-cpp-python
|
||||
```
|
||||
|
||||
Place your model under the models folder and launch the program. As always make sure the environment variables are passed to the program.
|
||||
|
||||
```
|
||||
HIP_VISIBLE_DEVICES=0 HSA_OVERRIDE_GFX_VERSION="10.3.0" python server.py
|
||||
```
|
||||
|
||||
You might not need to pass the variables if they are in your profile but I'm stressing how they are necessary here.
|
||||
|
||||
Point your browser to http://localhost:7860 and load the desired model from the web interface. This one can OOM if you load too many layers so you might need to actually adjust the value.
|
||||
|
||||
You need to activate the venv before launching it. **Having the same venv for all the programs or not using venv at all is not a good idea. These projects often use specific versions and you might end up with a dependency mess if**.
|
||||
|
||||
### Langchain
|
||||
|
||||
This follows a similar path from ooba since it uses llama-cpp-python.
|
||||
|
||||
```
|
||||
$ python3 -m venv langchain
|
||||
$ source langchain/bin/activate
|
||||
# for fish run "source langchain/bin/activate.fish" instead
|
||||
$ CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install --no-cache llama-cpp-python
|
||||
$ pip install langchain
|
||||
```
|
||||
|
||||
Read [Langchain llamacpp doc](https://python.langchain.com/docs/integrations/llms/llamacpp) and start coding. Alternatively you can setup an OpenAI compatible endpoint with pure llama.cpp in server mode or llama-cpp-python.
|
||||
16
notes/BTCD-PLAN9.md
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
- System is a pcengines APU2C2
|
||||
- 2GB DDR3
|
||||
- Some punny 4core AMD geode thing as the CPU
|
||||
- Totally headless. Access through serial
|
||||
- 1TB mSATA drive
|
||||
- 32GB sd card
|
||||
|
||||
- There is a FreeBSD install on the SD card. Good for rescuing.
|
||||
|
||||
- We are probably going to use ed as a text editor
|
||||
- Install and configure 9Front as a CPU server
|
||||
- Needs to adjust memory reserved for the kernel
|
||||
- Needs to setup networking
|
||||
- Access Rio (the UI) through a program call drawterm
|
||||
- Bootstrap Golang from source
|
||||
- Build BTCD
|
||||
308
notes/UDM-NIXOS.md
Normal file
|
|
@ -0,0 +1,308 @@
|
|||
# How I put NixOS on my UDM (trashcan model) router
|
||||
|
||||
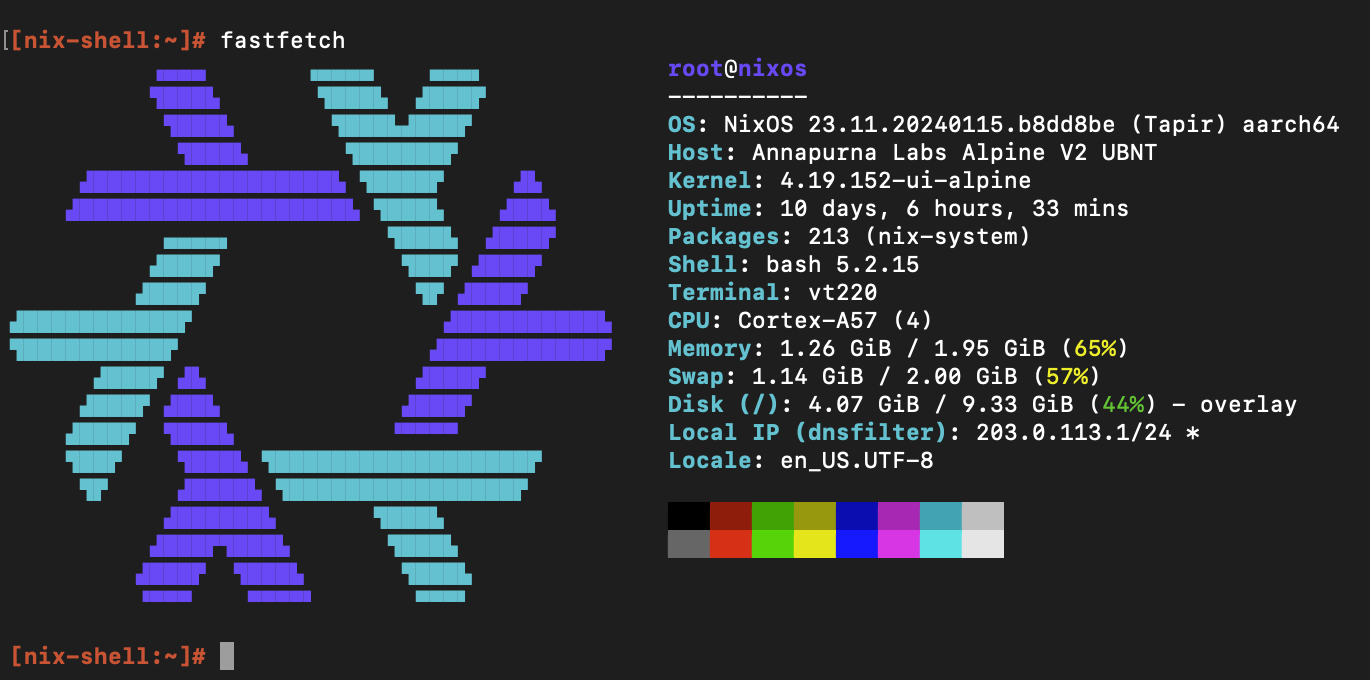
|
||||
*a rare cursed fetch!*
|
||||
|
||||
Content also available on [https://code.despera.space/iru/htdocs/src/branch/main/notes/UDM-NIXOS.md](https://code.despera.space/iru/htdocs/src/branch/main/notes/UDM-NIXOS.md)
|
||||
|
||||
Really it's just a running NixOS on systemd-nspawn thing.
|
||||
|
||||
The UDM product line basically runs on Linux kernel and userland. It is a
|
||||
surprisingly normal device that allows you to SSH and run commands. It even has
|
||||
apt and systemd services installed. The only catch being that for the most part
|
||||
the file system structure is immutable with only a few exceptions like /data and
|
||||
/etc/systemd. Previous versions even had the Unifi services running on a podman
|
||||
container. On recent versions of the firmware podman was phased out but we got
|
||||
something that resembles a more complete system structure as opposed to a
|
||||
busybox-like system.
|
||||
|
||||
So basically its some kind of Debian-based Linux running on a headless ARM64
|
||||
computer. Can we install and run stuff? Yes! In fact projects like
|
||||
https://github.com/unifi-utilities/unifios-utilities publish scripts to run
|
||||
general purpose programs and configurations on UDM. Be aware however that
|
||||
firmware upgrades might wipe the persistent data storage so don't put anything
|
||||
in there that you don't want to lose and preferably keep scripts so you can
|
||||
setup again after having its flash storage nuked by a major update.
|
||||
|
||||
I have the base UDM model. The first with the pill format that has been
|
||||
aparently replaced by the UDR. The UDR seems to have more features like Wifi6,
|
||||
bigger internal storage and even an SD card slot meant for vigilance camera
|
||||
footage storage but comes with a weaker CPU in comparison with the original
|
||||
UDM base. As far as I know the rack mountable models follow the same OS and
|
||||
file system structure.
|
||||
|
||||
|
||||
## Okay but why?
|
||||
|
||||
I'm gonna leave this to your imagination on why would you add services to your
|
||||
proprietary router applicance. To me its the fact that I don't really like
|
||||
running servers at home and I'm ultimately stuck with this router so why not
|
||||
put it to work maybe running a static webserver or something silly like Home
|
||||
Assistant. The truth of the matter is that I can't just leave things alone.
|
||||
|
||||
And if you can run Linux why would you run something that is not NixOS? Thats
|
||||
crazy and it doesn't make sense.
|
||||
|
||||
## How do we root the UDM? What kind of jailbreak do I need?
|
||||
|
||||
No.
|
||||
|
||||
You enable SSH from the Controller UI, log into it as root with the password you
|
||||
set to the admin user. You just waltz in and start installing and configuring.
|
||||
|
||||
```
|
||||
# apt update && apt install systemd-container
|
||||
```
|
||||
|
||||
Thats it. Kinda. The complicated part is modifying the programs to write into
|
||||
the persistent data directories while also making sure your stuff starts on
|
||||
boot and doesn't get wiped on minor firmware upgrades.
|
||||
|
||||
## Building the NixOS root image.
|
||||
|
||||
Might want to read first: [https://nixcademy.com/2023/08/29/nixos-nspawn/](https://nixcademy.com/2023/08/29/nixos-nspawn/)
|
||||
|
||||
We need a NixOS tarball image. TFC's https://github.com/tfc/nspawn-nixos
|
||||
contains the flake to build such an image and also publishes artifacts for AMD64
|
||||
but not ARM64. I guess you could build this from an AMD64 machine but I haven't
|
||||
looked into building a cross platform environment (didn't needed to compile
|
||||
anything though). I have a recent macbook with UTM so I just downloaded one of
|
||||
the default Linux virtual machine images from the UTM page and installed the
|
||||
Nix runtime over the OS.
|
||||
|
||||
Make sure you have git and curl installed.
|
||||
|
||||
```
|
||||
$ sh <(curl -L https://nixos.org/nix/install) --daemon
|
||||
```
|
||||
|
||||
You need to start another terminal session.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tfc/nspawn-nixos
|
||||
$ cd nspawn-nixos
|
||||
$ nix --extra-experimental-features 'nix-command flakes' build .
|
||||
```
|
||||
|
||||
Optionally you could try to edit the configuration to generate an image with
|
||||
everything you need. In case you need something like Home Assistant, some
|
||||
compilation might be necessary and although I haven't tried compiling code on
|
||||
the UDM I suspect it might be a painful process due to CPU performance and
|
||||
space constraints. Here is an [example with Home Assistant, Caddy and Tailscale](https://code.despera.space/iru/nspawn-nixos/src/branch/main/configuration.nix).
|
||||
|
||||
The image will be available under
|
||||
`./result/tarball/nixos-system-aarch64-linux.tar.xz`. Use scp to send this to
|
||||
the /data/ directory of the UDM.
|
||||
|
||||
## Installing the image
|
||||
|
||||
First we create the folder structure:
|
||||
|
||||
```
|
||||
# mkdir -p /data/custom/machines
|
||||
# ln -s /data/custom/machines /var/lib/machines
|
||||
```
|
||||
|
||||
Under normal circunstainces by now you would just run
|
||||
`machinectl import-tar /data/nixos-system-aarch64-linux.tar.xz <machinename>`
|
||||
however the version of tar that is present in this system doesn't really like
|
||||
the resulting tarball image. It will yeld errors like `Directory renamed before
|
||||
its status could be extracted`.
|
||||
|
||||
Thankfully we can install bsdtar through `apt install libarchive-tools` however
|
||||
`machinectl import-tar` is hardcoded to use the tar command. Adding a symlink
|
||||
from `/usr/bin/bsdtar` to `/usr/local/bin/tar` won't work since some parameters
|
||||
are used that are not supported in bsdtar. You could try writing a wrapper shell
|
||||
script but just unpacking the tarball directly was sufficient.
|
||||
|
||||
```
|
||||
# mkdir /var/lib/machines/udmnixos
|
||||
# bsdtar Jxvfp /data/nixos-system-aarch64-linux.tar.xz -C /var/lib/machines/udmnixos
|
||||
```
|
||||
|
||||
Lets start the container.
|
||||
|
||||
```
|
||||
# machinectl start udmnixos
|
||||
# machinectl
|
||||
MACHINE CLASS SERVICE OS VERSION ADDRESSES
|
||||
udmnixos container systemd-nspawn nixos 23.11 192.168.168.88…
|
||||
|
||||
```
|
||||
|
||||
Good. Now we need to change the root password.
|
||||
|
||||
```
|
||||
# machinectl shell udmnixos /usr/bin/env passwd
|
||||
Connected to machine udmnixos. Press ^] three times within 1s to exit session.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: password updated successfully
|
||||
Connection to machine udmnixos terminated.
|
||||
```
|
||||
|
||||
Finally we can login into the container.
|
||||
|
||||
```
|
||||
# machinectl login udmnixos
|
||||
Connected to machine udmnixos. Press ^] three times within 1s to exit session.
|
||||
|
||||
|
||||
<<< Welcome to NixOS 23.11.20240115.b8dd8be (aarch64) - pts/1 >>>
|
||||
|
||||
|
||||
nixos login: root
|
||||
Password:
|
||||
|
||||
[root@nixos:~]#
|
||||
```
|
||||
|
||||
We haven't finished yet. By default the network is set to its own container
|
||||
network. We also don't have a DNS resolver configured. You can leave that
|
||||
session with CTRL+]]].
|
||||
|
||||
https://www.freedesktop.org/software/systemd/man/latest/systemd-nspawn.html#-n
|
||||
|
||||
```
|
||||
# machinectl stop udmnixos
|
||||
```
|
||||
|
||||
## Networking and Persistence
|
||||
|
||||
The first thing that needs to be addressed is the DNS configuration. The default
|
||||
setting that copies the /etc/resolv.conf from host won't work since it points to
|
||||
localhost. Either install resolved, netmask or set a static DNS config.
|
||||
|
||||
As for the network method we have some options here.
|
||||
|
||||
- [Run using the default network stack and map ports to the container](https://www.freedesktop.org/software/systemd/man/latest/systemd-nspawn.html#-p).
|
||||
- Run using something akin to --network=host where the container has full access to the host network.
|
||||
- Give the container its own independent interface through a bridge.
|
||||
- [Give the container its own independent interface through macvlan](https://github.com/unifi-utilities/unifios-utilities/tree/main/nspawn-container#step-2a-configure-the-container-to-use-an-isolated-macvlan-network).
|
||||
|
||||
### Using --network-veth and port mapping
|
||||
|
||||
```
|
||||
# mkdir -p /etc/systemd/nspawn
|
||||
# cat > /etc/systemd/nspawn/udmnixos.nspawn <<HERE
|
||||
[Exec]
|
||||
Boot=on
|
||||
ResolvConf=off
|
||||
|
||||
[Network]
|
||||
Port=tcp:2222:22
|
||||
HERE
|
||||
|
||||
#machinectl enable udmnixos
|
||||
Created symlink /etc/systemd/system/machines.target.wants/systemd-nspawn@udmnixos.service → /lib/systemd/system/systemd-nspawn@.service
|
||||
|
||||
# machinectl start udmnixos
|
||||
```
|
||||
|
||||
Remember this will listen on ALL UDM interfaces so you might want to make sure
|
||||
the firewall rules will accomodate it.
|
||||
|
||||
```
|
||||
# iptables -t nat -L -n -v | grep 2222
|
||||
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:2222 ADDRTYPE match dst-type LOCAL to:192.168.206.200:22
|
||||
0 0 DNAT tcp -- * * 0.0.0.0/0 !127.0.0.0/8 tcp dpt:2222 ADDRTYPE match dst-type LOCAL to:192.168.206.200:22
|
||||
```
|
||||
|
||||
### Using the host network
|
||||
|
||||
This will give access to all the network interfaces. Any service that runs on
|
||||
the container will be accessible from the UDM interfaces without the need to
|
||||
map ports. The container will also have the same IP addresses as the UDM.
|
||||
|
||||
You might want to read about [capabilities](https://www.freedesktop.org/software/systemd/man/latest/systemd.nspawn.html#Capability=) if you plan on running some VPN
|
||||
software like Wireguard or Tailscale.
|
||||
|
||||
|
||||
```
|
||||
# mkdir -p /etc/systemd/nspawn
|
||||
# cat > /etc/systemd/nspawn/udmnixos.nspawn <<HERE
|
||||
[Exec]
|
||||
Boot=on
|
||||
#Daring are we?
|
||||
#Capability=all
|
||||
ResolvConf=off
|
||||
|
||||
[Network]
|
||||
Private=off
|
||||
VirtualEthernet=off
|
||||
HERE
|
||||
|
||||
#machinectl enable udmnixos
|
||||
Created symlink /etc/systemd/system/machines.target.wants/systemd-nspawn@udmnixos.service → /lib/systemd/system/systemd-nspawn@.service
|
||||
|
||||
# machinectl start udmnixos
|
||||
```
|
||||
|
||||
### Using a bridge to give the container its own interface
|
||||
|
||||
I had to give some capabilities to the container otherwise it wouldn't properly start. Replace the value of Bridge with the bridge corresponding to the UDM network you want to add. Normally these correspond to the VLAN id of that network. Use `brctl show` to find out.
|
||||
|
||||
```
|
||||
# mkdir -p /etc/systemd/nspawn
|
||||
# cat > /etc/systemd/nspawn/udmnixos.nspawn <<HERE
|
||||
[Exec]
|
||||
Boot=on
|
||||
Capability=CAP_NET_RAW,CAP_NET_ADMIN
|
||||
ResolvConf=off
|
||||
|
||||
[Network]
|
||||
Bridge=br2
|
||||
Private=off
|
||||
VirtualEthernet=off
|
||||
HERE
|
||||
|
||||
#machinectl enable udmnixos
|
||||
Created symlink /etc/systemd/system/machines.target.wants/systemd-nspawn@udmnixos.service → /lib/systemd/system/systemd-nspawn@.service
|
||||
|
||||
# machinectl start udmnixos
|
||||
# machinectl login udmnixos
|
||||
# machinectl login nixos
|
||||
Failed to get login PTY: No machine 'nixos' known
|
||||
root@UDM:/etc/systemd/nspawn# machinectl login udmnixos
|
||||
Connected to machine udmnixos. Press ^] three times within 1s to exit session.
|
||||
|
||||
|
||||
<<< Welcome to NixOS 23.11.20240518.e7cc617 (aarch64) - pts/1 >>>
|
||||
|
||||
|
||||
nixos login: root
|
||||
Password:
|
||||
|
||||
[root@nixos:~]# ifconfig
|
||||
host0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
|
||||
inet [redacted] netmask 255.255.255.192 broadcast [redacted]
|
||||
inet6 [redacted] prefixlen 64 scopeid 0x20<link>
|
||||
inet6 [redacted] prefixlen 64 scopeid 0x0<global>
|
||||
ether 92:01:4c:a7:a1:7b txqueuelen 1000 (Ethernet)
|
||||
RX packets 2415 bytes 611986 (597.6 KiB)
|
||||
RX errors 0 dropped 0 overruns 0 frame 0
|
||||
TX packets 61 bytes 5337 (5.2 KiB)
|
||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||
|
||||
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
|
||||
inet 127.0.0.1 netmask 255.0.0.0
|
||||
inet6 ::1 prefixlen 128 scopeid 0x10<host>
|
||||
loop txqueuelen 1000 (Local Loopback)
|
||||
RX packets 0 bytes 0 (0.0 B)
|
||||
RX errors 0 dropped 0 overruns 0 frame 0
|
||||
TX packets 0 bytes 0 (0.0 B)
|
||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||
|
||||
```
|
||||
|
||||
### MACVLAN isolation and more
|
||||
|
||||
Here is where some custom configuration might be needed. Read https://github.com/unifi-utilities/unifios-utilities/tree/main/nspawn-container
|
||||
to find out how to setup custom scripts.
|
||||
|
||||
## Persistence
|
||||
|
||||
As far as I verified by rebooting the UDM many times to write this note all
|
||||
configurations were preserved. According to [the article on nspawn-containers on the unifies-utilities project](https://github.com/unifi-utilities/unifios-utilities/tree/main/nspawn-container#step-3-configure-persistence-across-firmware-updates)
|
||||
although `/etc/systemd` and `/data` folders are preserved during firmware upgrades `/var/` and `/usr/` are not and there goes our packages and symlink. Please follow the steps on that
|
||||
page to setup persistence across firmware upgrades.
|
||||